7. Example Application Tutorial: Snakebin¶
Snakebin is a combination of Pastebin and JSFiddle, for Python. It allows a user to create and store Python scripts in ZeroCloud, retrieve them using a unique URL, and execute them through a web interface. Essentially this is a copy of the Go Playground, but for Python.
In this tutorial, we will be building the entire application from scratch and deploying it to ZeroCloud. The result will be a web application, complete with a REST API and a basic UI written in HTML and JavaScript. The entire backend for the REST API will be implemented in Python.
7.1. Overview¶
Jump to a section:
We will build the application in three parts. In the first part, we will implement a REST API for uploading and downloading Python scripts to/from ZeroCloud. We will also implment a basic UI to interact with the REST interface in HTML and JavaScript.
In the second part, we will add execution functionality to the API, as well as a “Run” button to the UI to execute code. The secure isolation of ZeroVM will ensure that any arbitrary code can run safely.
In the third and final part, we will implement a parallelized MapReduce-style search function for searching all existing documents in Snakebin. The search function will be driven by yet another addition to the API and will include a “Search” field in the UI.
7.2. Setup¶
The first thing you’ll need to do is set up a
development environment, including the python-swiftclient
and zpm command line tools.
Next, you should create a working directory on your local machine. In this
tutorial, we will put all project files in a directory called snakebin
inside the home directory. Change to this directory as well.
$ mkdir $HOME/snakebin
$ cd $HOME/snakebin
7.3. Swift Container Setup¶
To deploy and run the application, we’ll need three containers:
snakebin-api: This will serve as the base URL for REST API requests. This container will only contain the HTML / JavaScript UI files.snakebin-app: This will contain all of the application files, except for the UI files.snakebin-store: This will serve as our document storage location. No direct access will be allowed; all documents must be accessed through the REST API.
Go ahead and create these containers now. You can do this using the swift
command line tool:
$ swift post snakebin-api
$ swift post snakebin-app
$ swift post snakebin-store
Double-check that the containers were created:
$ swift list
snakebin-api
snakebin-app
snakebin-store
7.4. Add zapp.yaml¶
The next thing we need to do is add the basic configuration file which defines
a ZeroVM application (or “zapp”). zpm can do this for us:
$ zpm new --template python
This will create a zapp.yaml file in the current directory. Open
zapp.yaml in your favorite text editor. Change the execution section
execution:
groups:
- name: ""
path: file://python2.7:python
args: ""
devices:
- name: python2.7
- name: stdout
to look like this:
execution:
groups:
- name: "snakebin"
path: file://python2.7:python
args: "snakebin.py"
devices:
- name: python2.7
- name: stdout
content_type: message/http
- name: stdin
- name: input
path: swift://~/snakebin-store
Edit the bundling section
bundling: []
to include the source files for our application (which we will be creating below):
bundling: ["snakebin.py", "save_file.py", "get_file.py", "index.html"]
Finally, we need to specify third-party dependencies so that zpm knows how
to bundle our application:
dependencies: [
"falcon",
"six",
"mimeparse",
]
The final result should look like this:
project_type: python
execution:
groups:
- name: "snakebin"
path: file://python2.7:python
args: "snakebin.py"
devices:
- name: python2.7
- name: stdout
content_type: message/http
- name: stdin
- name: input
path: swift://~/snakebin-store
meta:
Version: ""
name: "snakebin"
Author-email: ""
Summary: ""
help:
description: ""
args: []
bundling: ["snakebin.py", "save_file.py", "get_file.py", "index.html"]
dependencies: [
"falcon",
"six",
"mimeparse",
]
7.5. Part 1: Upload/Download Scripts¶
First, we need to build an application for uploading and retrieving scripts, complete with a basic HTML user interface.
Before we dig into the application code, let’s think about our API design.
7.5.1. REST API¶
For the time being, we only need to support a few different types of requests:
GET /snakebin-api:- Get an empty HTML form for uploading a script.
POST /snakebin-api:- Post file contents, get a
/snakebin-api/:scriptURL back. GET /snakebin-api/:script:Retrieve uploaded file contents.
If a request specifies the header
Accept: text/html(as is the case with a web browser), load the HTML UI page with the script textarea populated. For any otherAcceptvalue, just return the raw script contents.
7.5.2. The Code¶
ZeroCloud provides a CGI-like environment for handling HTTP requests. A lot of what follows involves setting and reading environment variables and generating HTTP responses from scratch.
7.5.2.1. http_resp¶
Since generating HTTP responses is the most crucial part of this application,
let’s first define utility function for creating these responses. In your
snakebin working directory, create a file called snakebin.py. Then add
the following code to it:
def http_resp(code, reason, content_type='message/http', msg='',
extra_headers=None):
if extra_headers is None:
extra_header_text = ''
else:
extra_header_text = '\r\n'.join(
['%s: %s' % (k, v) for k, v in extra_headers.items()]
)
extra_header_text += '\r\n'
resp = """\
HTTP/1.1 %(code)s %(reason)s\r
%(extra_headers)sContent-Type: %(content_type)s\r
Content-Length: %(msg_len)s\r
\r
%(msg)s"""
resp %= dict(code=code, reason=reason, content_type=content_type,
msg_len=len(msg), msg=msg, extra_headers=extra_header_text)
sys.stdout.write(resp)
Notice the last line, which is highlighted: sys.stdout.write(resp).
The ZeroCloud execution environment handles most communication between parts of
an application through /dev/stdout, by convention. To your application code
(which is running inside the ZeroVM virtual execution environment),
/dev/stdout looks just like the character device you would expect in a
Linux-like execution environment, but to ZeroCloud, you can write to this
device to either communicate to a client or start a new “job”, all using HTTP.
(In this tutorial, we’ll be doing both.)
For http_resp, we’ll need to import sys from the standard library. Add
an import statement to the top of the file:
import sys
7.5.2.2. Job¶
A “job” is defined by a collection of JSON objects which specify commands to execute, environment variables to set (for the execution environment), and device mappings. ZeroCloud consumes job descriptions to start new jobs, which can consist of one or more program execution groups. For the moment, we’ll only be dealing with single program jobs. (In part three, we’ll need to define some multi-group jobs to implement the MapReduce search function. But don’t worry about that for now.)
Tip
For complete details on structure and options for a job description, check out the full documentation.
Let’s create a class which will help us generate these jobs. Add the class
below to snakebin.py. For simplicity, some Swift object/container names are
hard-coded.
class Job(object):
def __init__(self, name, args):
self.name = name
self.args = args
self.devices = [
{'name': 'python2.7'},
{'name': 'stdout', 'content_type': 'message/http'},
{'name': 'image', 'path': 'swift://~/snakebin-app/snakebin.zapp'},
]
self.env = {}
def add_device(self, name, content_type=None, path=None):
dev = {'name': name}
if content_type is not None:
dev['content_type'] = content_type
if path is not None:
dev['path'] = path
self.devices.append(dev)
def set_envvar(self, key, value):
self.env[key] = value
def to_json(self):
return json.dumps([self.to_dict()])
def to_dict(self):
return {
'name': self.name,
'exec': {
'path': 'file://python2.7:python',
'args': self.args,
'env': self.env,
},
'devices': self.devices,
}
This class makes use of the json module, so lets import that as well:
import json
7.5.2.3. GET and POST handling¶
Now we’re getting into the core functionality of our application. It’s time to
add code to handle the POST and GET requests in the manner that we’ve
defined in our API definition above.
To make things easy for us, we can write this functionality as a WSGI application and use light-weight API framework like Falcon to implement the various endpoint handlers.
We’ll need to add a handful of new things to snakebin.py:
- a utility function to query container databases to check if an object with a given name already exists
- a utility function to generate a random “short name”, using script upload contents as the random seed
- a couple of “handler” classes and some helper functions for dealing with the various types of requests
- a
mainblock which sets up the WSGI application and registers the endpoint handlers
Here’s what that looks like:
def _object_exists(name):
"""Check the local container (mapped to `/dev/input`) to see if it contains
an object with the given ``name``. /dev/input is expected to be a sqlite
database.
"""
conn = sqlite3.connect('/dev/input')
try:
cur = conn.cursor()
sql = 'SELECT ROWID FROM object WHERE name=? AND deleted=0'
cur.execute(sql, (name, ))
result = cur.fetchall()
return len(result) > 0
finally:
conn.close()
def random_short_name(seed, length=10):
rand = random.Random()
rand.seed(seed)
name = ''.join(rand.sample(string.ascii_lowercase
+ string.ascii_uppercase
+ string.digits, length))
return name
def _handle_script(req, resp, account, container, script):
# Go get the requested script, or 404 if it doesn't exist.
if _object_exists(script):
private_file_path = 'swift://~/snakebin-store/%s' % script
job = Job('snakebin-get-file', 'get_file.py')
job.add_device('input', path=private_file_path)
job.set_envvar('HTTP_ACCEPT', os.environ.get('HTTP_ACCEPT'))
# Setting this header and content_type will make ZeroCloud
# intercept the request and spawn a new job, instead of responding
# directly to the client.
resp.set_header('X-Zerovm-Execute', '1.0')
resp.content_type = 'application/json'
resp.status = falcon.HTTP_200
resp.body = job.to_json()
else:
resp.status = falcon.HTTP_404
def _handle_script_upload(req, resp, account, container, script=None):
file_data = req.stream.read()
file_hash = hashlib.sha1(file_data)
short_name = random_short_name(file_hash.hexdigest())
snakebin_file_path = 'swift://~/snakebin-store/%s' % short_name
public_file_path = 'swift://~/snakebin-api/%s' % short_name
if _object_exists(short_name):
# This means the file already exists. No problem!
# Since the short url is derived from the hash of the contents,
# just return a URL to the file.
path = '/api/%s/%s/%s' % (account, container, short_name)
file_url = urlparse.urlunparse((
'http',
os.environ.get('HTTP_HOST'),
path,
None,
None,
None
)) + '\n'
resp.status = falcon.HTTP_200
resp.body = file_url
else:
# Go and save the file.
# We need to spawn another ZeroVM job to write this file.
job = Job('snakebin-save-file', 'save_file.py')
job.set_envvar('SNAKEBIN_POST_CONTENTS',
base64.b64encode(file_data))
job.set_envvar('SNAKEBIN_PUBLIC_FILE_PATH', public_file_path)
job.add_device('output', path=snakebin_file_path,
content_type='text/plain')
# Setting this header and content_type will make ZeroCloud
# intercept the request and spawn a new job, instead of responding
# directly to the client.
resp.set_header('X-Zerovm-Execute', '1.0')
resp.content_type = 'application/json'
resp.status = falcon.HTTP_200
resp.body = job.to_json()
class RootHandler(object):
def on_get(self, req, resp, account, container):
"""Serve a blank index.html page."""
with open('index.html') as fp:
resp.body = fp.read()
resp.content_type = 'text/html; charset=utf-8'
resp.status = falcon.HTTP_200
def on_post(self, req, resp, account, container):
"""Handle the form post/script upload."""
_handle_script_upload(req, resp, account, container)
class ScriptHandler(object):
def on_get(self, req, resp, account, container, script):
_handle_script(req, resp, account, container, script)
def on_post(self, req, resp, account, container, script):
# Also allow new/modified scripts to be uploaded when the client is on
# a page like `/snakebin-api/Wg4re8mXbV`.
_handle_script_upload(req, resp, account, container, script=script)
if __name__ == '__main__':
app = falcon.API()
app.add_route('/{account}/{container}', RootHandler())
app.add_route('/{account}/{container}/{script}', ScriptHandler())
handler = wsgiref.handlers.SimpleHandler(
sys.stdin,
sys.stdout,
sys.stderr,
environ=dict(os.environ),
multithread=False,
)
handler.run(app)
This codes makes use of more standard library modules, so we need to add import statements for those, as well as falcon, a third party library.
import base64
import hashlib
import json
import os
import random
import sqlite3
import string
import sys
import urlparse
import wsgiref.handlers
import falcon
Your snakebin.py file should now look something like this:
import base64
import hashlib
import json
import os
import random
import sqlite3
import string
import sys
import urlparse
import wsgiref.handlers
import falcon
def http_resp(code, reason, content_type='message/http', msg='',
extra_headers=None):
if extra_headers is None:
extra_header_text = ''
else:
extra_header_text = '\r\n'.join(
['%s: %s' % (k, v) for k, v in extra_headers.items()]
)
extra_header_text += '\r\n'
resp = """\
HTTP/1.1 %(code)s %(reason)s\r
%(extra_headers)sContent-Type: %(content_type)s\r
Content-Length: %(msg_len)s\r
\r
%(msg)s"""
resp %= dict(code=code, reason=reason, content_type=content_type,
msg_len=len(msg), msg=msg, extra_headers=extra_header_text)
sys.stdout.write(resp)
class Job(object):
def __init__(self, name, args):
self.name = name
self.args = args
self.devices = [
{'name': 'python2.7'},
{'name': 'stdout', 'content_type': 'message/http'},
{'name': 'image', 'path': 'swift://~/snakebin-app/snakebin.zapp'},
]
self.env = {}
def add_device(self, name, content_type=None, path=None):
dev = {'name': name}
if content_type is not None:
dev['content_type'] = content_type
if path is not None:
dev['path'] = path
self.devices.append(dev)
def set_envvar(self, key, value):
self.env[key] = value
def to_json(self):
return json.dumps([self.to_dict()])
def to_dict(self):
return {
'name': self.name,
'exec': {
'path': 'file://python2.7:python',
'args': self.args,
'env': self.env,
},
'devices': self.devices,
}
def _object_exists(name):
"""Check the local container (mapped to `/dev/input`) to see if it contains
an object with the given ``name``. /dev/input is expected to be a sqlite
database.
"""
conn = sqlite3.connect('/dev/input')
try:
cur = conn.cursor()
sql = 'SELECT ROWID FROM object WHERE name=? AND deleted=0'
cur.execute(sql, (name, ))
result = cur.fetchall()
return len(result) > 0
finally:
conn.close()
def random_short_name(seed, length=10):
rand = random.Random()
rand.seed(seed)
name = ''.join(rand.sample(string.ascii_lowercase
+ string.ascii_uppercase
+ string.digits, length))
return name
def _handle_script(req, resp, account, container, script):
# Go get the requested script, or 404 if it doesn't exist.
if _object_exists(script):
private_file_path = 'swift://~/snakebin-store/%s' % script
job = Job('snakebin-get-file', 'get_file.py')
job.add_device('input', path=private_file_path)
job.set_envvar('HTTP_ACCEPT', os.environ.get('HTTP_ACCEPT'))
# Setting this header and content_type will make ZeroCloud
# intercept the request and spawn a new job, instead of responding
# directly to the client.
resp.set_header('X-Zerovm-Execute', '1.0')
resp.content_type = 'application/json'
resp.status = falcon.HTTP_200
resp.body = job.to_json()
else:
resp.status = falcon.HTTP_404
def _handle_script_upload(req, resp, account, container, script=None):
file_data = req.stream.read()
file_hash = hashlib.sha1(file_data)
short_name = random_short_name(file_hash.hexdigest())
snakebin_file_path = 'swift://~/snakebin-store/%s' % short_name
public_file_path = 'swift://~/snakebin-api/%s' % short_name
if _object_exists(short_name):
# This means the file already exists. No problem!
# Since the short url is derived from the hash of the contents,
# just return a URL to the file.
path = '/api/%s/%s/%s' % (account, container, short_name)
file_url = urlparse.urlunparse((
'http',
os.environ.get('HTTP_HOST'),
path,
None,
None,
None
)) + '\n'
resp.status = falcon.HTTP_200
resp.body = file_url
else:
# Go and save the file.
# We need to spawn another ZeroVM job to write this file.
job = Job('snakebin-save-file', 'save_file.py')
job.set_envvar('SNAKEBIN_POST_CONTENTS',
base64.b64encode(file_data))
job.set_envvar('SNAKEBIN_PUBLIC_FILE_PATH', public_file_path)
job.add_device('output', path=snakebin_file_path,
content_type='text/plain')
# Setting this header and content_type will make ZeroCloud
# intercept the request and spawn a new job, instead of responding
# directly to the client.
resp.set_header('X-Zerovm-Execute', '1.0')
resp.content_type = 'application/json'
resp.status = falcon.HTTP_200
resp.body = job.to_json()
class RootHandler(object):
def on_get(self, req, resp, account, container):
"""Serve a blank index.html page."""
with open('index.html') as fp:
resp.body = fp.read()
resp.content_type = 'text/html; charset=utf-8'
resp.status = falcon.HTTP_200
def on_post(self, req, resp, account, container):
"""Handle the form post/script upload."""
_handle_script_upload(req, resp, account, container)
class ScriptHandler(object):
def on_get(self, req, resp, account, container, script):
_handle_script(req, resp, account, container, script)
def on_post(self, req, resp, account, container, script):
# Also allow new/modified scripts to be uploaded when the client is on
# a page like `/snakebin-api/Wg4re8mXbV`.
_handle_script_upload(req, resp, account, container, script=script)
if __name__ == '__main__':
app = falcon.API()
app.add_route('/{account}/{container}', RootHandler())
app.add_route('/{account}/{container}/{script}', ScriptHandler())
handler = wsgiref.handlers.SimpleHandler(
sys.stdin,
sys.stdout,
sys.stderr,
environ=dict(os.environ),
multithread=False,
)
handler.run(app)
7.5.2.4. get_file.py and save_file.py¶
In snakebin.py, there are some references to additional source files to
handle saving and retrieval of uploaded documents. Let’s create those now.
get_file.py:
import os
from xml.sax.saxutils import escape
import snakebin
if __name__ == '__main__':
with open('/dev/input') as fp:
contents = fp.read()
http_accept = os.environ.get('HTTP_ACCEPT', '')
if 'text/html' in http_accept:
# Something that looks like a browser is requesting the document:
with open('/index.html') as fp:
html_page_template = fp.read()
html_page = html_page_template.replace('{code}', escape(contents))
snakebin.http_resp(200, 'OK', content_type='text/html; charset=utf-8',
msg=html_page)
else:
# Some other type of client is requesting the document:
snakebin.http_resp(200, 'OK', content_type='text/plain', msg=contents)
save_file.py:
import base64
import os
import snakebin
def save_file(post_contents, public_file_path):
script_contents = base64.b64decode(post_contents)
with open('/dev/output', 'a') as fp:
fp.write(script_contents)
_rest, container, short_name = public_file_path.rsplit('/', 2)
file_url = 'http://%(host)s/api/%(acct)s/%(cont)s/%(short_name)s\n'
file_url %= dict(host=os.environ.get('HTTP_HOST'), cont=container,
acct=os.environ.get('PATH_INFO').strip('/'),
short_name=short_name)
snakebin.http_resp(201, 'Created', msg=file_url)
if __name__ == '__main__':
post_contents = os.environ.get('SNAKEBIN_POST_CONTENTS')
public_file_path = os.environ.get('SNAKEBIN_PUBLIC_FILE_PATH')
save_file(post_contents, public_file_path)
7.5.2.5. User Interface¶
To complete the first iteration of the Snakebin application, let’s create a
user interface. Create a file called index.html and add the following code
to it:
<!DOCTYPE html>
<html>
<head>
<title>Snakebin</title>
<link rel="stylesheet" href="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/codemirror.min.css">
<script src="//cdnjs.cloudflare.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/codemirror.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/mode/python/python.min.js"></script>
<script>
$(document).ready(function() {
// Add syntax highlighting for Python code:
var code = $('#code')[0];
var editor = CodeMirror.fromTextArea(code, {
mode: "text/x-python",
lineNumbers: true
});
// Called when a script posting is successful.
var saveSuccess = function(data, textStatus, jqXHR) {
var url = jqXHR.responseText;
$('#save-status').html(
'Saved to <a id="save-url" href="' + url
+ '">' + url + '</a>'
);
};
// Attach save functionality to the "Save" button
$('#save').click(function() {
var request = {
'url': window.location.href,
'type': 'post',
'data': editor.getValue(),
'headers': {
'X-Zerovm-Execute': 'api/1.0'
},
'success': saveSuccess
};
$.ajax(request);
});
});
</script>
</head>
<body>
<textarea id="code" rows="15" cols="80" wrap="off"
autocorrect="off" autocomplete="off"
autocapitalize="off" spellcheck="false">{code}</textarea>
<p>
<input id="save" type="submit" value="Save" />
<div id="save-status"></div>
</p>
</body>
</html>
7.5.3. Bundle and deploy¶
Bundle:
$ zpm bundle
created snakebin.zapp
Deploy:
$ zpm deploy snakebin-app snakebin.zapp
app deployed to http://127.0.0.1:8080/v1/AUTH_123def/snakebin-app/
Setting an environment variable for the storage account ID will make commands more concise and convenient to execute:
$ export OS_STORAGE_ACCOUNT=AUTH_123def...
Configure the endpoint handler zapp for snakebin-api, snakebin-app, and
snakebin-store:
$ swift post --header "X-Container-Meta-Rest-Endpoint: swift://$OS_STORAGE_ACCOUNT/snakebin-app/snakebin.zapp" snakebin-api
$ swift post --header "X-Container-Meta-Rest-Endpoint: swift://$OS_STORAGE_ACCOUNT/snakebin-app/snakebin.zapp" snakebin-app
$ swift post --header "X-Container-Meta-Rest-Endpoint: swift://$OS_STORAGE_ACCOUNT/snakebin-app/snakebin.zapp" snakebin-store
We’ll also need to set execution permissions for unauthenticated (anonymous) users on the same three containers:
$ swift post --header "X-Container-Meta-Zerovm-Suid: .r:*,.rlistings" snakebin-api
$ swift post --header "X-Container-Meta-Zerovm-Suid: .r:*,.rlistings" snakebin-app
$ swift post --header "X-Container-Meta-Zerovm-Suid: .r:*,.rlistings" snakebin-store
7.5.4. Test¶
Now that the first working part of our application is deployed, let’s test uploading and retrieving some text.
First, create a file called example.py, and add any text to it. For
example:
print "hello world!"
Now upload it:
$ curl -X POST -H "X-Zerovm-Execute: api/1.0" $OS_STORAGE_URL/snakebin-api --data-binary @example.py
http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/GDHh7vR3Zb
The URL returned from the POST can be used to retrieve the document:
$ curl http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/GDHh7vR3Zb
print "hello world!"
Note
Note that in the POST we have to supply the
X-Zerovm-Execute: api/1.0 header because this tells ZeroCloud how to
interpret the request. Alternatively, you can change the /v1/ part of
the URL to /api/ to make requests simpler, and also to accomodate
simpler GET requests, using curl (as is shown above) or a web
browser.
We can also try this through the web interface. Open a web browser and go to
http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api. You should get a
page that looks something like this:

Type some text into the box and play around with saving documents. You can also
try to browse the the document we created above on the command line
(http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/GDHh7vR3Zb).
7.6. Part 2: Execute Scripts¶
In this part, we’ll add on to what we’ve built so far and allow Python scripts to be executed by Snakebin.
7.6.1. API updates¶
To support script execution via HTTP (either from the command line or browser), we will need to add a couple more endpoints to our API:
GET /snakebin-api/:script/execute:- Execute the specified
:scriptand return the output as text. The script must already exist and be available at/snakebin-api/:script. POST /snakebin-api/execute:- Execute the contents of the request as a Python script and return the output as text.
The following changes will implement these two endpoints.
7.6.2. The Code¶
We need to add a couple of things to support script execution. First, we need to add a utility function to just execute code, and second, we need to update the endpoint handlers to support execution.
First, we need to tweak _handle_script to support execution:
def _handle_script(req, resp, account, container, script, execute=False):
# Go get the requested script, or 404 if it doesn't exist.
if _object_exists(script):
private_file_path = 'swift://~/snakebin-store/%s' % script
job = Job('snakebin-get-file', 'get_file.py')
job.add_device('input', path=private_file_path)
job.set_envvar('HTTP_ACCEPT', os.environ.get('HTTP_ACCEPT'))
if execute:
job.set_envvar('SNAKEBIN_EXECUTE', 'True')
# Setting this header and content_type will make ZeroCloud
# intercept the request and spawn a new job, instead of responding
# directly to the client.
resp.set_header('X-Zerovm-Execute', '1.0')
resp.content_type = 'application/json'
resp.status = falcon.HTTP_200
resp.body = job.to_json()
else:
resp.status = falcon.HTTP_404
Next, add an execute_code utility function, which actually do the execution:
def execute_code(code):
# Patch stdout, so we can capture output from the submitted code
old_stdout = sys.stdout
new_stdout = StringIO.StringIO()
sys.stdout = new_stdout
# Create a module with the code
module = imp.new_module('dontcare')
module.__name__ = "__main__"
# Execute the submitted code
exec code in module.__dict__
# Read the response from the code
new_stdout.seek(0)
output = new_stdout.read()
# Unpatch stdout
sys.stdout = old_stdout
return output
execute_code requires the imp and StringIO standard library modules,
so we need to import those:
import base64
import hashlib
import imp
import json
import os
import random
import sqlite3
import string
import StringIO
import sys
import urlparse
import wsgiref.handlers
import falcon
Next, update the ScriptHandler class (to support direct POSTing of scripts
for execution):
class ScriptHandler(object):
def on_get(self, req, resp, account, container, script):
_handle_script(req, resp, account, container, script)
def on_post(self, req, resp, account, container, script):
if script == 'execute':
file_data = req.stream.read()
resp.content_type = 'text/plain'
resp.status = falcon.HTTP_200
resp.body = execute_code(file_data)
else:
# Also allow new/modified scripts to be uploaded when the client is
# on a page like `/snakebin-api/Wg4re8mXbV`.
_handle_script_upload(req, resp, account, container, script=script)
and add a new ScriptExecuteHandler class:
class ScriptExecuteHandler(object):
def on_get(self, req, resp, account, container, script):
_handle_script(req, resp, account, container, script, execute=True)
Finally, we need to register the new handler (and add a comment to explain some
new behavior for ScriptHandler):
if __name__ == '__main__':
app = falcon.API()
app.add_route('/{account}/{container}', RootHandler())
# Handles `POST /{account}/{container}/execute` as well
app.add_route('/{account}/{container}/{script}', ScriptHandler())
app.add_route('/{account}/{container}/{script}/execute',
ScriptExecuteHandler())
handler = wsgiref.handlers.SimpleHandler(
sys.stdin,
sys.stdout,
sys.stderr,
environ=dict(os.environ),
multithread=False,
)
handler.run(app)
Now we need to make some modifications to get_file.py to allow execution
of a script. We need to read the SNAKEBIN_EXECUTE environment variable
and execute a script if it is present. Update get_file.py to this:
import os
from xml.sax.saxutils import escape
import snakebin
if __name__ == '__main__':
with open('/dev/input') as fp:
contents = fp.read()
http_accept = os.environ.get('HTTP_ACCEPT', '')
execute = os.environ.get('SNAKEBIN_EXECUTE', None)
if 'text/html' in http_accept:
# Something that looks like a browser is requesting the document:
if execute is not None:
output = snakebin.execute_code(contents)
snakebin.http_resp(200, 'OK',
content_type='text/html; charset=utf-8',
msg=output)
else:
with open('/index.html') as fp:
html_page_template = fp.read()
html_page = html_page_template.replace('{code}',
escape(contents))
snakebin.http_resp(200, 'OK',
content_type='text/html; charset=utf-8',
msg=html_page)
else:
# Some other type of client is requesting the document:
output = contents
if execute is not None:
output = snakebin.execute_code(contents)
snakebin.http_resp(200, 'OK', content_type='text/plain', msg=output)
We now need to update the UI with a “Run” button to hook in the execution
functionality. Update your index.html to look like this:
<!DOCTYPE html>
<html>
<head>
<title>Snakebin</title>
<link rel="stylesheet" href="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/codemirror.min.css">
<script src="//cdnjs.cloudflare.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/codemirror.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/mode/python/python.min.js"></script>
<script>
$(document).ready(function() {
// Add syntax highlighting for Python code:
var code = $('#code')[0];
var editor = CodeMirror.fromTextArea(code, {
mode: "text/x-python",
lineNumbers: true
});
// Called when a script posting is successful.
var saveSuccess = function(data, textStatus, jqXHR) {
var url = jqXHR.responseText;
$('#save-status').html(
'Saved to <a id="save-url" href="' + url
+ '">' + url + '</a>'
);
};
// Attach save functionality to the "Save" button
$('#save').click(function() {
var request = {
'url': window.location.href,
'type': 'post',
'data': editor.getValue(),
'headers': {
'X-Zerovm-Execute': 'api/1.0'
},
'success': saveSuccess
};
$.ajax(request);
});
// Called when a script execution is successful.
var runSuccess = function(data, textStatus, jqXHR) {
var statusText = '';
statusText += textStatus;
statusText += ', X-Nexe-Retcode: ' + jqXHR.getResponseHeader('X-Nexe-Retcode');
statusText += ', X-Nexe-Status: ' + jqXHR.getResponseHeader('X-Nexe-Status');
$('#run-status').text(statusText);
// Convert newlines to br tags and display execution output
$('#run-output').html(jqXHR.responseText.replace(/\n/g, '<br />'));
};
// Attach run functionality to the "Run" button
$('#run').click(function() {
var execUrl = (window.location.href.split('snakebin-api')[0]
+ 'snakebin-api/execute');
var request = {
'url': execUrl,
'type': 'post',
'data': editor.getValue(),
'headers': {
'X-Zerovm-Execute': 'api/1.0'
},
'success': runSuccess
};
$.ajax(request);
});
});
</script>
</head>
<body>
<textarea id="code" rows="15" cols="80" wrap="off"
autocorrect="off" autocomplete="off"
autocapitalize="off" spellcheck="false">{code}</textarea>
<p>
<input id="save" type="submit" value="Save" />
<input id="run" type="submit" value="Run" />
<div id="save-status"></div>
</p>
<hr />
<p>Status:</p>
<div id="run-status"></div>
<hr />
<p>Output:</p>
<div id="run-output"></div>
</body>
</html>
7.6.3. Redeploy the application¶
First, rebundle your application files:
$ zpm bundle
To redeploy, we’ll use the same zpm command as before, but we’ll need to
specify the --force flag, since we’re deploying to an un-empty container:
$ zpm deploy snakebin-app snakebin.zapp --force
7.6.4. Test¶
First, let’s try executing one of the scripts we already uploaded. This can be
done simply by curl``ing the URL of the script and appending ``/execute:
$ curl http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/GDHh7vR3Zb/execute
hello world!
Next, let’s trying posting the example.py script directly to the
/snakebin-api/execute endpoint:
$ curl -X POST http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/execute --data-binary @example.py
hello world!
Let’s also test the functionality in the web browser. If you nagivate to
http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api, the new page
should look something like this:
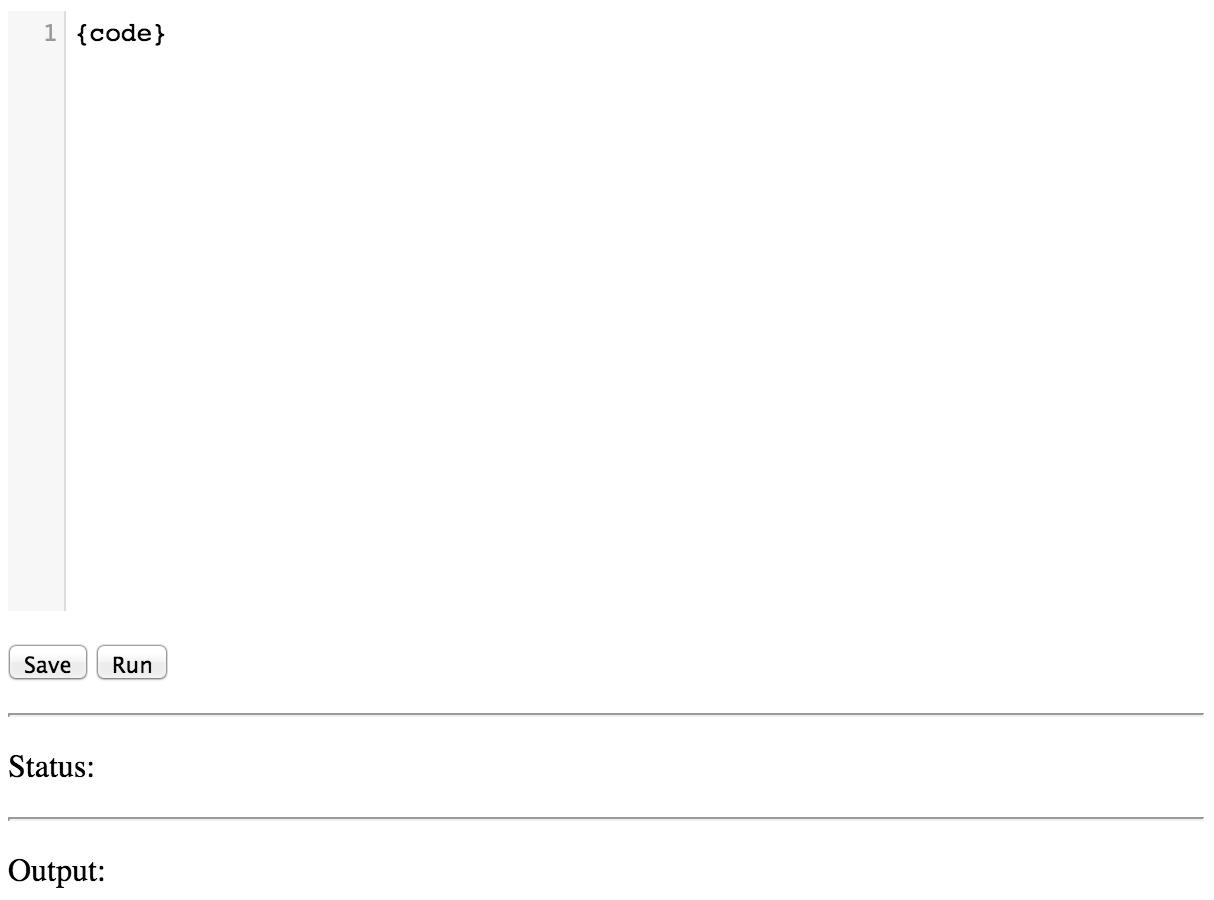
Try writing some code into the text box and click Run to execute them.
Try also accessing the /snakebin-api/:script/execute endpoint directly
in the browser using the same the URL in the POST example above:
http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/GDHh7vR3Zb/execute
7.7. Part 3: Search Scripts¶
The final piece of Snakebin is a simple search search mechanism, which will find
document which contain a given search term. All documents in snakebin-store
will be searched in a parallelized fashion using the MapReduce semantics of
ZeroCloud.
7.7.1. API updates¶
The final endpoint we’ll add to our API is search:
GET /snakebin-api/search?q=:term:- Return a JSON list of URLs to the documents (in
snakebin-store) which contain:term. When this endpoint is hit, a MapReduce job of multiple nodes will be spawned to perform the search.
7.7.2. The Code¶
For the MapReduce job, we need to add two new Python modules.
search_mapper.py
import os
with open('/dev/input') as fp:
contents = fp.read()
search_term = os.environ.get('SNAKEBIN_SEARCH')
if search_term in contents:
document_name = os.environ.get('LOCAL_PATH_INFO').split('/')[-1]
doc_url = 'http://%(host)s/api/%(acct)s/%(cont)s/%(short_name)s\n'
doc_url %= dict(host=os.environ.get('HTTP_HOST'), cont='snakebin-api',
acct=os.environ.get('PATH_INFO').strip('/'),
short_name=document_name)
with open('/dev/out/search-reducer', 'a') as fp:
fp.write(doc_url)
search_reducer.py
import json
import os
import snakebin
inp_dir = '/dev/in'
results = []
for inp_file in os.listdir(inp_dir):
with open(os.path.join(inp_dir, inp_file)) as fp:
result = fp.read().strip()
if result:
results.append(result)
snakebin.http_resp(200, 'OK', content_type='application/json',
msg=json.dumps(results))
These two files will handle the bulk of the search operation.
To kick off the search, we need to make some more changes to
snakebin.py. First, add a _handle_search utility function:
def _handle_search(req, resp, account, container):
query = urllib.unquote(req.params.get('q'))
mapper_job = Job('search-mapper', 'search_mapper.py')
mapper_job.add_device('input', path='swift://~/snakebin-store/*')
mapper_job.set_envvar('SNAKEBIN_SEARCH', query)
mapper_job.set_envvar('HTTP_ACCEPT',
os.environ.get('HTTP_ACCEPT', ''))
mapper_dict = mapper_job.to_dict()
mapper_dict['connect'] = ['search-reducer']
reducer_job = Job('search-reducer', 'search_reducer.py')
reducer_dict = reducer_job.to_dict()
map_reduce_job = json.dumps([mapper_dict, reducer_dict])
resp.body = map_reduce_job
resp.set_header('X-Zerovm-Execute', '1.0')
resp.content_type = 'application/json'
resp.status = falcon.HTTP_200
sys.stderr.write('submitting search job')
_handle_search needs the urllib module from the standard library, so we
must import it:
import base64
import hashlib
import imp
import json
import os
import random
import sqlite3
import string
import StringIO
import sys
import urllib
import urlparse
import wsgiref.handlers
import falcon
Finally, we need to make one small tweak to ScriptHandler to hook in the
search function:
class ScriptHandler(object):
def on_get(self, req, resp, account, container, script):
if script == 'search':
_handle_search(req, resp, account, container)
else:
_handle_script(req, resp, account, container, script)
def on_post(self, req, resp, account, container, script):
if script == 'execute':
file_data = req.stream.read()
resp.content_type = 'text/plain'
resp.status = falcon.HTTP_200
resp.body = execute_code(file_data)
else:
# Also allow new/modified scripts to be uploaded when the client is
# on a page like `/snakebin-api/Wg4re8mXbV`.
_handle_script_upload(req, resp, account, container, script=script)
Now for the final changes to the user interface:
<!DOCTYPE html>
<html>
<head>
<title>Snakebin</title>
<link rel="stylesheet" href="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/codemirror.min.css">
<script src="//cdnjs.cloudflare.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/codemirror.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/codemirror/4.6.0/mode/python/python.min.js"></script>
<script>
$(document).ready(function() {
// Add syntax highlighting for Python code:
var code = $('#code')[0];
var editor = CodeMirror.fromTextArea(code, {
mode: "text/x-python",
lineNumbers: true
});
// Called when a script posting is successful.
var saveSuccess = function(data, textStatus, jqXHR) {
var url = jqXHR.responseText;
$('#save-status').html(
'Saved to <a id="save-url" href="' + url
+ '">' + url + '</a>'
);
};
// Attach save functionality to the "Save" button
$('#save').click(function() {
var request = {
'url': window.location.href,
'type': 'post',
'data': editor.getValue(),
'headers': {
'X-Zerovm-Execute': 'api/1.0'
},
'success': saveSuccess
};
$.ajax(request);
});
// Called when a script execution is successful.
var runSuccess = function(data, textStatus, jqXHR) {
var statusText = '';
statusText += textStatus;
statusText += ', X-Nexe-Retcode: ' + jqXHR.getResponseHeader('X-Nexe-Retcode');
statusText += ', X-Nexe-Status: ' + jqXHR.getResponseHeader('X-Nexe-Status');
$('#run-status').text(statusText);
// Convert newlines to br tags and display execution output
$('#run-output').html(jqXHR.responseText.replace(/\n/g, '<br />'));
};
// Attach run functionality to the "Run" button
$('#run').click(function() {
var execUrl = (window.location.href.split('snakebin-api')[0]
+ 'snakebin-api/execute');
var request = {
'url': execUrl,
'type': 'post',
'data': editor.getValue(),
'headers': {
'X-Zerovm-Execute': 'api/1.0'
},
'success': runSuccess
};
$.ajax(request);
});
// Call when search is successful.
var searchSuccess = function(data, textStatus, jqXHR) {
var urls = JSON.parse(jqXHR.responseText);
var results = '';
for (var i = 0; i < urls.length; i++) {
var url = urls[i];
results += '<a href="' + url + '">' + url + '</a><br />';
}
$('#search-results').html(results);
$('#search-results').css('visibility', 'visible');
};
// Attach search funcionality to the "Search" button
$('#search').click(function() {
var searchTerm = encodeURIComponent($('#search-text').val());
var searchUrl = (window.location.href.split('snakebin-api')[0]
+ 'snakebin-api/search?q=' + searchTerm);
var request = {
'url': searchUrl,
'type': 'get',
'success': searchSuccess
};
$.ajax(request);
});
});
</script>
</head>
<body>
<p>
<input id="search-text" type="input">
<input id="search" type="submit" value="Search">
<div id="search-results" style="visibility: hidden;"></div>
</p>
<hr />
<textarea id="code" rows="15" cols="80" wrap="off"
autocorrect="off" autocomplete="off"
autocapitalize="off" spellcheck="false">{code}</textarea>
<p>
<input id="save" type="submit" value="Save" />
<input id="run" type="submit" value="Run" />
<div id="save-status"></div>
</p>
<hr />
<p>Status:</p>
<div id="run-status"></div>
<hr />
<p>Output:</p>
<div id="run-output"></div>
</body>
</html>
We also need to update the zapp.yaml to include the new Python files.
Update the bundling section:
bundling: ["snakebin.py", "save_file.py", "get_file.py", "index.html",
"search_mapper.py", "search_reducer.py"]
7.7.3. Redeploy the application¶
Just as we did before in part 2, we need to redeploy
the application, using zpm:
$ zpm bundle
$ zpm deploy snakebin-app snakebin.zapp --force
7.7.4. Test¶
First, let’s try executing the search on the command line. (You should post a couple of a scripts to Snakebin first, otherwise your search won’t return anything, obviously.)
$ curl http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/search?q=foo
["http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/IOFW0Z8UYR", "http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api/e2X0hNA9ld"]
Let’s also test the functionality in the web browser. If you navigate to
http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api, the new page
should look something like this:
http://127.0.0.1:8080/api/$OS_STORAGE_ACCOUNT/snakebin-api, the new page
should look something like this:
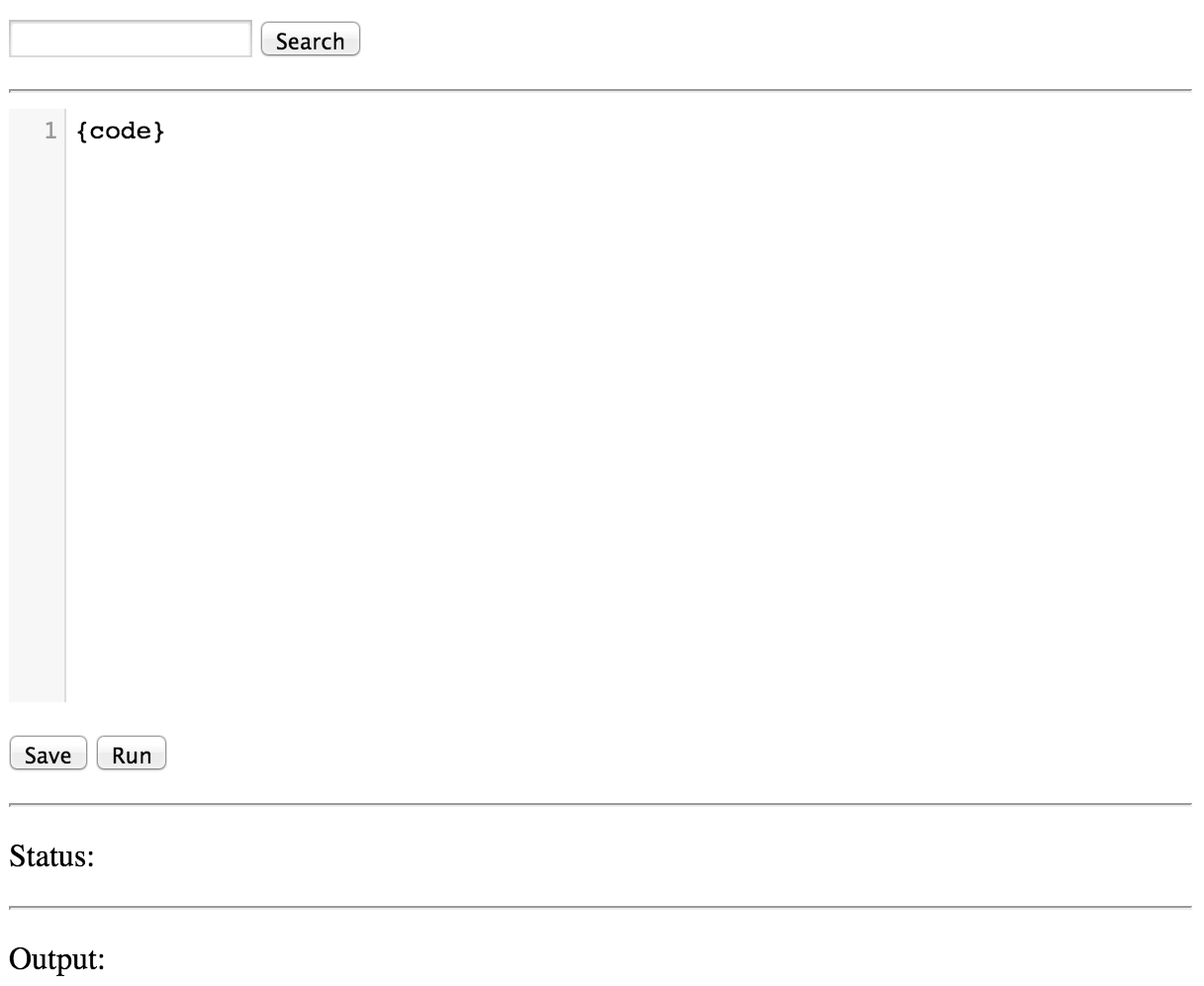
Try typing in a search term and clicking “Search”.
Try also accessing the /snakebin-api/search?q=:term endpoint directly in
the browser.